Triton 编程范式入门
前言
此文档面向「有 CUDA 编程基础」的同学,通过 CUDA vs Triton 对比的方式,帮助你快速理解 Triton 的编程范式。本文将从最简单的向量加法入手,展示两种编程模型的核心差异,并通过实际代码示例帮助你建立从 CUDA 到 Triton 的思维转换。
期望在阅读完本文后,你能够理解 Triton 的核心抽象思想,掌握其基本语法,并能够将简单的 CUDA Kernel 改写为 Triton 版本。
一、从向量加法看两种编程范式
向量加法是最简单的并行任务,非常适合用来对比 CUDA 和 Triton 的编程思想差异。我们先从任务本身说起。
1. 任务描述
给定两个长度为 N 的向量 x 和 y,计算 out[i] = x[i] + y[i],输出新的向量 out。这是一个典型的 element-wise 操作,每个输出元素的计算都是独立的,天然适合并行化。
2. CUDA 实现:线程级并行
在 CUDA 中,你需要思考:每个线程处理哪个元素?
__global__ void vector_add_cuda(float *x, float *y, float *out, int n) {
// 每个线程计算自己的全局索引
int idx = blockIdx.x * blockDim.x + threadIdx.x;
// 边界检查
if (idx < n) {
out[idx] = x[idx] + y[idx]; // 每个线程处理一个元素
}
}
// Host 端调用
int main() {
int N = 10000000;
// ... 省略内存分配和数据初始化 ...
int blockSize = 256; // 每个 Block 有 256 个线程
int numBlocks = (N + blockSize - 1) / blockSize;
vector_add_cuda<<<numBlocks, blockSize>>>(cuda_x, cuda_y, cuda_out, N);
cudaDeviceSynchronize();
return 0;
}
在 CUDA 的编程模型中,你需要将任务分解到每一个线程。每个线程就像一个独立的工人,负责处理一个元素。线程通过 blockIdx 和 threadIdx 这两个内置变量计算出自己负责的全局索引 idx,然后访问对应位置的数据。由于数组长度 n 可能不是 Block 大小的整数倍,我们需要用 if (idx < n) 来做边界检查,但这可能导致 Warp Divergence,影响性能。
3. Triton 实现:数据块级并行
在 Triton 中,你需要思考:每个 Program Instance 处理哪批元素?
import torch
import triton
import triton.language as tl
@triton.jit
def vector_add_triton(
x_ptr, # 输入向量 x 的指针
y_ptr, # 输入向量 y 的指针
out_ptr, # 输出向量 out 的指针
n_elements, # 向量长度
BLOCK_SIZE: tl.constexpr, # 每个 Program 处理的元素数(编译时常量)
):
# 1. 获取当前 Program 的 ID(类似 blockIdx.x)
pid = tl.program_id(axis=0)
# 2. 计算当前 Program 负责的元素范围
block_start = pid * BLOCK_SIZE
offsets = block_start + tl.arange(0, BLOCK_SIZE)
# offsets 是一个向量!例如:[0, 1, 2, ..., BLOCK_SIZE-1]
# 3. 创建边界检查的 mask(向量化的边界检查)
mask = offsets < n_elements
# 4. 向量化加载数据(一次加载 BLOCK_SIZE 个元素)
x = tl.load(x_ptr + offsets, mask=mask)
y = tl.load(y_ptr + offsets, mask=mask)
# 5. 向量化计算
out = x + y
# 6. 向量化存储
tl.store(out_ptr + offsets, out, mask=mask)
# Host 端调用
def add(x: torch.Tensor, y: torch.Tensor):
assert x.is_cuda and y.is_cuda, "输入必须在 GPU 上"
assert x.shape == y.shape, "输入形状必须一致"
out = torch.empty_like(x)
n_elements = out.numel()
# 计算需要多少个 Program Instance
grid = lambda meta: (triton.cdiv(n_elements, meta['BLOCK_SIZE']),)
# 启动 Kernel
vector_add_triton[grid](x, y, out, n_elements, BLOCK_SIZE=1024)
return out
# 使用示例
if __name__ == "__main__":
N = 10_000_000
x = torch.randn(N, device='cuda', dtype=torch.float32)
y = torch.randn(N, device='cuda', dtype=torch.float32)
out = add(x, y)
# 验证正确性
expected = x + y
assert torch.allclose(out, expected), "结果不匹配!"
相比之下,Triton 的编程模型更像是把线程们组织成团队。每个 Program Instance 处理一批元素(BLOCK_SIZE 个),而不是单个元素。你通过 tl.arange 生成一个向量化的偏移量数组,这个数组包含了当前 Program 要处理的所有元素的索引。边界检查也变成了向量化的操作:mask = offsets < n_elements 会生成一个布尔向量,标记哪些位置是有效的。这种向量化的 mask 机制可以有效避免 Warp Divergence。实际上,Triton 中的所有操作都是向量化的(SIMD),这是它和 CUDA 最本质的区别。
二、核心概念对比
1. 概念映射表
| CUDA 概念 | Triton 概念 | 说明 |
|---|---|---|
__global__ | @triton.jit | Kernel 函数标记 |
| Thread | 不存在 | Triton 不暴露线程概念 |
| Block | Program Instance | 并行执行的基本单元 |
blockIdx.x | tl.program_id(axis=0) | 获取当前 Block/Program 的 ID |
threadIdx.x | 不存在 | Triton 自动向量化 |
blockDim.x | BLOCK_SIZE | 每个 Block 处理的元素数 |
idx = blockIdx.x * blockDim.x + threadIdx.x | offsets = pid * BLOCK_SIZE + tl.arange(0, BLOCK_SIZE) | 索引计算方式不同 |
if (idx < n) | mask = offsets < n | 边界检查方式不同 |
x[idx] | tl.load(x_ptr + offsets, mask=mask) | 内存访问方式不同 |
out[idx] = value | tl.store(out_ptr + offsets, value, mask=mask) | 内存写入方式不同 |
__syncthreads() | 自动处理 | Triton 不需要手动同步 |
2. 线程索引 vs 向量化偏移
这是 CUDA 和 Triton 最核心的区别。
CUDA:标量索引
// 每个线程计算自己的索引(标量)
int idx = blockIdx.x * blockDim.x + threadIdx.x;
// 访问一个元素
float val = x[idx];
在 CUDA 中,你的思考方式是:"我是第 idx 号线程,我处理第 idx 个元素"。这是一种非常直观的一对一映射关系。
Triton:向量偏移
# 每个 Program 计算一批偏移量(向量)
pid = tl.program_id(axis=0)
offsets = pid * BLOCK_SIZE + tl.arange(0, BLOCK_SIZE)
# 访问一批元素
x = tl.load(x_ptr + offsets, mask=mask)
而在 Triton 中,你需要转变思维:"我是第 pid 号 Program,我处理第 [start, start+1, ..., start+BLOCK_SIZE-1] 批元素"。这里最关键的区别在于,CUDA 的 idx 是一个标量(单个整数),而 Triton 的 offsets 是一个向量(整数数组)。
3. 边界检查:if vs mask
CUDA 的方式
if (idx < n) {
out[idx] = x[idx] + y[idx]; // 可能导致 Warp Divergence
}
使用标量 if 的问题在于,同一个 Warp 内的 32 个线程可能会因为边界条件走不同的分支。比如在最后一个 Block 中,前面的线程满足 idx < n 继续执行,而后面的线程不满足条件被过滤掉。这种分支分歧(Divergence)会导致 Warp 内的线程无法同步执行,从而降低性能。
Triton 的方式
mask = offsets < n_elements # 向量化比较,生成布尔向量
x = tl.load(x_ptr + offsets, mask=mask) # 只加载有效位置
out = x + y
tl.store(out_ptr + offsets, out, mask=mask) # 只存储有效位置
Triton 的 mask 机制则完全不同。mask = offsets < n_elements 是一个向量化的比较操作,会生成一个布尔向量。在 tl.load 和 tl.store 中使用 mask 时,编译器会生成 predicated instructions(带谓词的指令),这是 GPU 硬件原生支持的特性。每个线程都有独立的 predicate 寄存器,可以在不引起分支的情况下选择性地执行指令。这样既保证了正确性,又避免了 Warp Divergence,代码还更简洁。
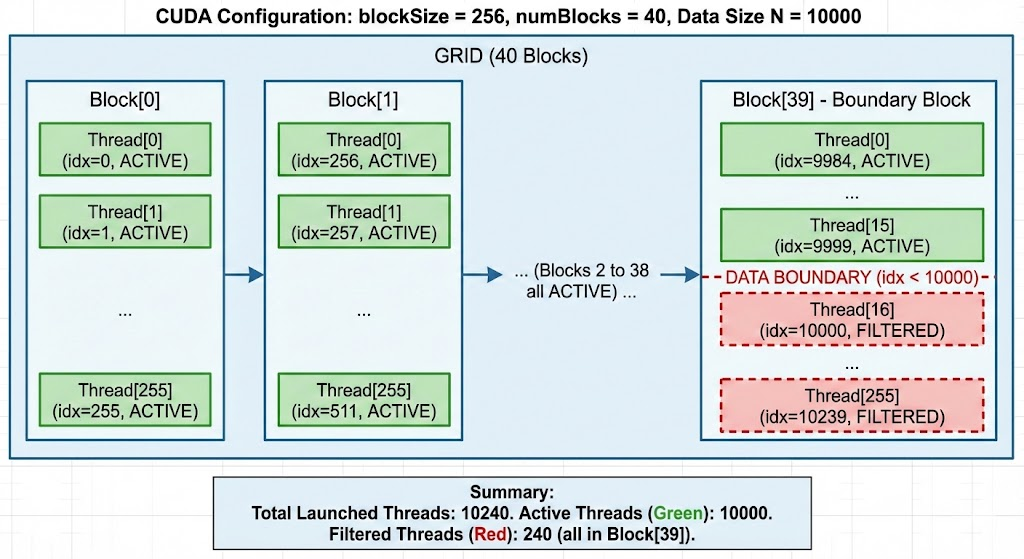
4. 具体示例:处理 10000 个元素
假设我们要处理 N = 10000 个元素。
CUDA 的执行方式
Triton 的执行方式
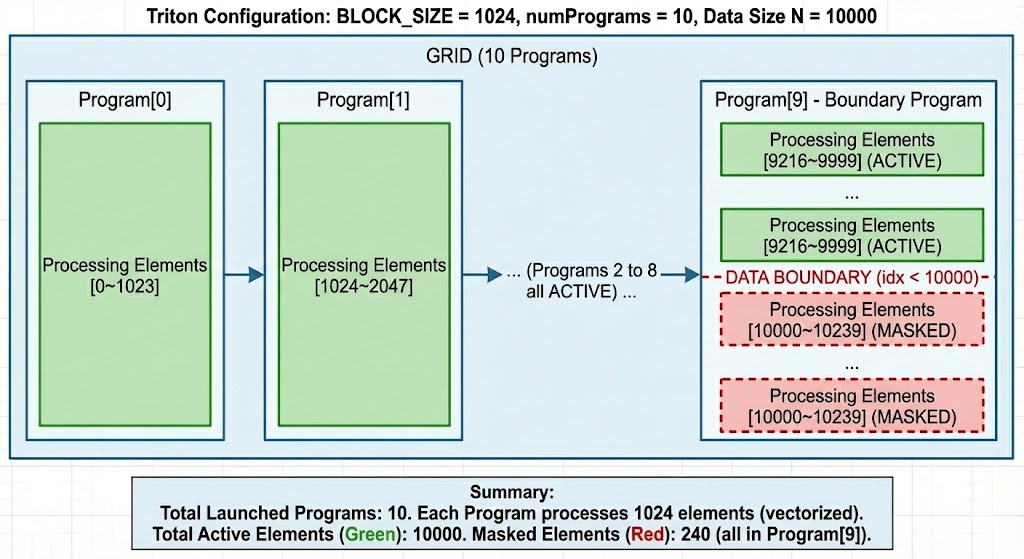
从这个例子可以看出,CUDA 启动了 10240 个线程,你需要思考"我是第几号线程"。而 Triton 只启动了 10 个 Program Instance,你要思考的是"我处理哪批数据"。这种抽象层次的提升,让代码更简洁,也更容易理解。
三、Grid 配置对比
CUDA 的 Grid 配置
int blockSize = 256; // 每个 Block 有 256 个线程
int numBlocks = (n + blockSize - 1) / blockSize; // 向上取整
my_kernel<<<numBlocks, blockSize>>>(args);
在 CUDA 中,你需要同时指定 numBlocks(有多少个 Block)和 blockSize(每个 Block 有多少个 Thread)。blockSize 的选择受到 SM 资源的限制,通常设置为 128/256/512。如果设置得太大,会因为寄存器和 Shared Memory 的限制导致 Occupancy 下降。
Triton 的 Grid 配置
BLOCK_SIZE = 1024 # 每个 Program Instance 处理 1024 个元素
grid = lambda meta: (triton.cdiv(n_elements, meta['BLOCK_SIZE']),)
my_kernel[grid](args, BLOCK_SIZE=BLOCK_SIZE)
Triton 的 Grid 配置则简单得多,你只需要指定 BLOCK_SIZE(每个 Program 处理多少元素),Grid 的大小会通过 triton.cdiv(n, BLOCK_SIZE) 自动计算。这里有一个重要的概念需要澄清:Triton 的 BLOCK_SIZE 并不等同于 CUDA 的 blockDim.x。CUDA 的 blockDim.x 表示线程数,而 Triton 的 BLOCK_SIZE 表示元素数。Triton 编译器会根据你指定的 BLOCK_SIZE,自动选择合适的线程配置来映射这些元素。
根据经验,Triton 的 BLOCK_SIZE 通常设置为 1024/2048/4096,比 CUDA 的 blockDim 要大得多。建议从 1024 开始尝试,然后根据实际性能进行调整。
四、课后练习
请打开 homework.ipynb 完成以下练习:练习 1 实现 AXPY 操作(),巩固基本的向量化加载和存储;练习 2 实现 1D 卷积,体会如何用向量化方式处理滑动窗口操作。每个练习都包含了测试函数和思考题。
五、常见问题 FAQ
Q1: Triton 内部到底有没有线程?性能会比 CUDA 差吗
A: 从硬件执行层面看,Triton 代码最终仍然运行在 GPU 的线程和 warp 上,只是 Triton 提供了更高层次的编程抽象,不直接暴露线程和 block 的概念。Triton 编译器会将向量化的程序描述转换为高效的 PTX / SASS,并映射到底层 GPU 执行模型。在性能方面,对于简单算子(如 element-wise 或带宽受限算子),Triton 通常可以达到接近手写 CUDA 的性能;对于高度优化的复杂算子(如 Flash Attention),Triton 在实践中也能达到与优化 CUDA 实现相当、或略低的性能水平。相比之下,Triton 在开发效率和可维护性方面通常具有明显优势。
Q2: mask 操作会导致性能下降吗?(类似 Warp Divergence)
A: Triton 的 mask 是向量化语义,编译器通常会将其生成 predicated instructions(带谓词的指令),而不是显式的分支跳转,因此不会像 CUDA 中不当使用 if 那样引入严重的 warp divergence。 在大多数连续访问、边界检查类场景中,mask 带来的性能开销较小;但如果 mask 覆盖比例很大或访问模式高度稀疏,仍然可能造成一定的算力浪费。总体而言,mask 是 Triton 中推荐且高效的边界处理方式。
Q3: 什么时候不能用 Triton
A: 以下场景建议使用 CUDA:
- 需要显式管理 Shared Memory 布局(如手动消除 Bank Conflicts)
- 需要使用 Warp-level primitives(
__shfl_,__ballot_,__syncwarp) - 需要动态并行(Dynamic Parallelism)
- 算法严重依赖线程间细粒度通信
- 需要与现有 CUDA 代码库深度集成
Q4: 如何从 CUDA 代码迁移到 Triton
A: 五步迁移法:
识别数据访问模式:你的 Kernel 主要做什么?(element-wise、reduction、matmul?)
改变思维方式:
- ❌ "每个线程处理第
idx个元素" - ✅ "每个 Program 处理第
[start...end]批元素"
- ❌ "每个线程处理第
转换索引计算:
// CUDA
int idx = blockIdx.x * blockDim.x + threadIdx.x;# Triton
pid = tl.program_id(0)
offsets = pid * BLOCK_SIZE + tl.arange(0, BLOCK_SIZE)转换边界检查:
// CUDA
if (idx < n) { ... }# Triton
mask = offsets < n转换内存访问:
// CUDA
float x = x_ptr[idx];
out[idx] = result;# Triton
x = tl.load(x_ptr + offsets, mask=mask)
tl.store(out_ptr + offsets, result, mask=mask)
六、学习检查清单
完成本小节后,你应该能够理解 Triton 的 Program Instance 概念以及它和 CUDA Block 的本质区别,掌握用 tl.arange 生成向量化偏移来代替 CUDA 的线程索引计算,理解 Triton 的 mask 如何优雅地避免 Warp Divergence,能够将简单的 CUDA element-wise Kernel 改写为 Triton 版本,并深刻理解 Triton 的抽象级别是 Block-level 而非 Thread-level。
下表展示了从 CUDA 思维到 Triton 思维的转变:
| ❌ CUDA 思维 | ✅ Triton 思维 |
|---|---|
"这个线程处理第 idx 个元素" | "这个 Program 处理第 [start, ..., end] 批元素" |
"idx 是一个整数" | "offsets 是一个整数向量" |
"用 if (idx < n) 检查边界" | "用 mask = offsets < n 向量化检查" |
"直接访问 x[idx]" | "显式 tl.load(x_ptr + offsets)" |
附:参考资料
下一步:完成所有练习后,进入 02: 内存与数据搬运,学习更复杂的内存访问模式!